이전 포스팅 에서 Replication 이 무엇인지, ISR 은 무엇인지 설명했다. 하지만 해당 포스팅만 가지고는 ISR 이 어떤 의미를 갖는 지 명확한 이해가 어려워 추가적으로 공부를 하고 정리를 할 필요를 느꼈다.
In-Sync Replica
ISR 의 존재 의의(?) 에 대해 이해를 하고자 하면, 카프카 프로듀서의 acks 옵션에 대한 이해가 필요하다. 해서, 해당 내용을 먼저 짚고 넘어가보려 한다.
ACKS
acks 는 간단하게 말해 확인의 의미이다. 프로듀서가 메시지를 보내고, 브로커에 잘 전달되었는 지 확인하기 위한 옵션으로 [1, 0, -1(all)] 값으로 설정할 수 있다.
acks = 0 프로듀서가 메시지를 보내고, 브로커에게 메시지 전달이 정상적으로 되었는 지를 확인하지 않는다. 메시지를 보내기만 하기 때문에, 성능 면에서는 세 가지 옵션 중 가장 월등하지만 메시지 전달이 정상적으로 되고 있는 지를 보장하지 않는다. 이 옵션은 메시지 유실보다 메시지 처리량이 더 중요하게 생각될 때 적용할 수 있다.
acks = 1 프로듀서가 메시지를 보내고, 앞선 포스팅에서 설명한 리더에게 메시지가 제대로 전달되었는 지를 확인한다. 리더는 메시지를 받아 로그 파일에 이를 추가하고, 다른 팔로워들이 메시지를 복제하는 것을 기다리지 않고 잘 전달되었다고 프로듀서에게 알린다. 이 옵션은 리더가 메시지를 받은 것을 보장하지만, 복제가 되었는 지를 확인하지 않기 때문에 리더가 메시지를 받고 바로 장애가 발생할 경우 메시지가 유실될 수 있다. 세 옵션 중, 지연 시간 / 처리량 / 안정성 면에서 가장 중도의 길을 걷는 옵션이다.
acks = all (-1) 프로듀서가 메시지를 보내고, 리더와 ISR 팔로워들이 메시지를 모두 전달받았는 지를 확인한다. 리더는 모든 ISR 들이 메시지를 복제했음을 확인한 뒤 프로듀서에게 메시지의 전달이 잘 이루어졌다고 알린다. 이 옵션을 적용하면, 메시지의 전달에 있어 상대적으로 매우 긴 시간이 필요하지만, 다른 옵션들에 비해 월등한 안정성을 제공한다.
시스템에 따라 어떤 옵션을 사용할 지는 차이가 있다. 안정성이 중요한 경우, acks=all 옵션을 사용할 것이고 처리량이 중요한 경우, acks=0 옵션을 사용할 수 있다. 둘 모두 적당히 필요할 경우 acks=1 을 사용할 수 있다. 옵션 중 어떤 것이 더 좋고 나쁨의 개념이 아니기 때문에 옵션에 따른 동작을 잘 이해하고 사용하는 것이 중요할 것 같다.
What is ISR for?
ISR 이 무엇인지는 지난 포스팅에서 설명했으니 넘어가고, ISR 이 대체 왜 필요한 지를 살펴보자. ISR 은 카프카에서 Latency 와 Safety 간 Tradeoff 로서 작용한다. 프로듀서 입장에서 봤을 때, 메시지 손실이 발생하는 것이 시스템에 끔찍한 문제를 가져온다면 acks=all 옵션을 적용해 모든 ISR 들이 메시지를 복제한 것을 확인할 것이다. 근데 이 때, 하나의 복제본이 사라지거나 지연된다면 전체 파티션이 느려지거나 사용할 수 없는 문제로 이어질 수 있다. 결국 ISR 이 존재하는 목적은, Replica 들이 느려지거나 죽은 경우에도 Fault Tolerant 한 시스템을 유지하는 것이다.
ISR 은 이전에 설명했듯, 내부의 팔로워들이 지속적으로 리더의 메시지를 풀링해 동기화를 유지해야 하고 빠른 성능을 제공할 수 있어야 한다. 빠르게 응답이 불가능하다면 해당 팔로워는 ISR 에서 제외될 것이다. 근데 만약, 모든 팔로워들이 느려져서 ISR 내에 리더만 존재하는 경우가 생긴다면 어떻게 될까?
프로듀서는 메시지의 유실을 막기 위해 모든 ISR 이 메시지를 저장한 것을 확인하는데, ISR 내에 리더만 존재하기 때문에 acks=1 옵션과 동일하게 동작할 것이다. 결국 acks=all 옵션을 적용했음에도 메시지 유실에 대한 가능성이 충분히 존재하게 된다.
이를 막기 위한 방안으로, min.insync.replicas 라는 옵션이 존재한다. 이 옵션값이 2로 설정되면, ISR 내에 하나의 replica 만 존재할 경우 전달받는 메시지를 거절한다. 이것이 메시지 유실을 막기 위한 safety 를 위해 존재하는 ISR 의 존재 의의라 볼 수 있다.
Minimum In-Sync Replica
min.insyc.replicas 는 위에서 설명했듯 프로듀서가 정상적으로 메시지를 전달하기 위해 ISR 내의 replica 가 최소 몇 개 존재해야 하는 지를 의미한다. 이 값은 크게 설정할 경우, 그만큼 데이터 안정성이 보장된다고 할 수 있지만 반면에 가용성을 하락시킬 수 있다. 예를 들어 노드가 3개 존재할 때 min.insync.replicas 를 3으로 설정하면, 하나의 노드만 장애가 발생해도 어떤 메시지도 받을 수 없게 된다.
이 옵션은 메시지 처리량에 직접적으로 영향을 주지 않는다. 직접적으로 영향을 주는 옵션은 위에서 본 프로듀서의 acks 옵션이고, 이 옵션은 데이터의 유실을 막기 위한 옵션으로 생각하면 된다.
Kafka 는 Fault Tolerant 를 위해 Replication 을 지원한다. Replication 이 무엇인지 간단하게 말하자면, 메시지를 복제해 관리하고 이를 통해 특정 브로커에 장애가 발생해도 다른 브로커가 해당 브로커의 역할을 대신할 수 있도록 하는 것이다.
Replication Factor
Replication Factor 는 토픽의 파티션의 복제본을 몇 개를 생성할 지에 대한 설정이다. 카프카에서는 Replication Factor 를 임의로 지정해 토픽을 생성할 수 있는데, Factor 를 2 로 설정하면 복제본을 한 개 생성하고 3 으로 설정하면 두 개의 복제본을 생성한다는 의미이다. 이해를 위해 다음의 그림을 통해 설명을 덧붙이겠다.
위의 그림은 topic01 과 topic02 모두 replication factor 를 1로 설정한 경우이다. (여기서 Partition 은 고려하지 않겠다.) 이에 대해 topic01 는 replication.factor 를 2로, topic02 는 3으로 설정한 경우를 다음 그림에서 볼 수 있다.
이와 같이 Replication Factor 를 조정해 replication 의 수를 몇 개로 설정할 지 관리자가 조정할 수 있다. replication 수가 많을수록 브로커 장애 시 토픽에 저장된 데이터의 안전성이 보장되기 때문에 중요 데이터의 경우는 replication factor 를 크게 설정하는 것이 좋다. 물론 replication 이 많아지면 그만큼 데이터의 복제로 인한 성능 하락이 있을 수 있기 때문에 무조건 크게 설정하는 것이 권장되지는 않는다.
Leader & Follower
Rabbit MQ 의 경우 복제본이 2개 존재하는 경우 하나를 Master, 다른 하나를 Mirrored 라 표현하는데 이러한 용어는 어플리케이션마다 상이하다. Kafka 에서는 Leader / Follower 라는 용어를 사용하는데, 위 그림에서 Replication 을 표현했던 것에 Leader, Follower 를 연결해 보자.
topic01 은 두 개의 복제본을 가지고 있어 하나는 Leader / 다른 하나는 Follower 로 구성되고, topic02 는 하나의 Leader / 두 개의 Follower 로 구성된다. 카프카는 Leader 에게 특별한 기능을 부여했는데, 그 기능이란 다음과 같다.
Topic 으로 통하는 모든 데이터의 Read/Write 는 오직 Leader 를 통해서 이루어진다.
위와 같이 기능을 하기 위해, 리더는 항상 정상적으로 동작해야 한다. 하지만 어떻게 그렇게 할 수 있을까? 리더도 똑같은 브로커 중 하나일 뿐인데 장애가 발생하지 않으리란 보장이 있을까?
답을 간단하게 얘기하자면, 리더와 팔로워는 변경될 수 있다. 카프카는 리더가 장애가 발생하면 기존의 팔로워 중 하나가 리더가 될 수 있는 Failover 방식을 채용하고 있다. 자세한 것은 아래의 ISR 에서 이어서 설명하겠다.
ISR (In-Sync Replication)
ISR 이라는 용어는 다소 생소하지만 간단하게 얘기하면 Replication Group 이라 표현할 수 있다. 위에서 토픽 별로 Replication Factor 를 설정해 Replication 을 생성했는데, 각각의 토픽으로 묶인 Replication 들을 ISR 이라 칭한다.
위 그림에서 보는 것과 같이 하나의 ISR 에는 하나의 Leader 와 n 개의 Follower 가 존재한다. ISR 의 규칙은 다음과 같다.
ISR 내의 모든 Follower 들은 Leader 가 될 수 있다.
Broker Down Situation
위의 규칙으로 인해 리더가 장애가 발생할 경우 ISR 내의 팔로워 중 하나가 리더가 되는 것이다. 이 부분에 대해서는 추가적으로 설명이 필요하다. 우선은 장애가 발생했을 때 어떤 일들이 벌어지는 지 그림과 같이 이해해보자.
만약 위와 같이 broker1 이 down 되었다고 하자. topic01 의 리더와 topic02 의 팔로워가 다운되었기 때문에 다음과 같은 변화가 생긴다.
topic01 의 경우, ISR 내에 하나의 팔로워가 존재하고, 위에서 설명한 누구든 ISR 내의 follower 는 leader 가 될 수 있다는 조건을 충족하기에 기존의 팔로워가 새로운 리더가 된다. 이때, 일시적으로 리더가 존재하지 않기 때문에 Read/Write 의 Timeout 이 발생할 수 있지만, Retry 가 일어나면 새로운 리더에 Read/Write 할 수 있으므로 장애 상황은 아니다.
topic02 는 팔로워 하나가 다운되었고, 다운된 팔로워가 ISR 에서 제외된다. topic01 과 다르게 리더는 변하지 않았기 때문에 아무런 특이사항 없이 read/write 가 계속 이루어진다.
추가적으로 브로커 2까지 다운되었다고 가정해보자. topic01 의 경우 ISR 내의 더 이상의 팔로워가 없기 때문에 리더를 넘겨줄 수 없고, 리더가 없기 때문에 read/write 를 지속할 수 없다. 즉, topic01 의 경우는 read/write 가 불가능한 장애 상황이 된 것이다. topic02 의 경우는 ISR 내에 남은 팔로워가 있기 때문에 해당 팔로워가 리더를 이어받아 read/write 를 지속한다.
위의 예제를 통해, 브로커에 장애가 발생한 경우 리더가 어떻게 변경되고, ISR 이 변경되는지 설명했다. 추가적으로 이와 같은 동작을 위해 카프카가 내부적으로 어떤 동작들을 하는 지 알아보자.
먼저 우리가 토픽을 만들고 옵션으로 Replication Factor 를 설정하면, 설정에 맞게 위의 예제와 같이 ISR 이 구성된다. ISR 이 구성되면 리더와 팔로워는 각자 역할이 주어지고 그 역할을 수행하기 시작하는데, 그 역할은 다음과 같다.
Leader : 팔로워를 감시하고 팔로워들 중 자신보다 일정 기간 뒤쳐진 팔로워가 발생하면 해당 팔로워가 리더가 될 자격이 없다고 판단하고, 뒤쳐진 팔로워를 ISR 에서 제외한다. Follower : 리더와 동일한 내용을 유지하기 위해 일정 주기마다 리더로부터 데이터를 가져온다.
위에서 설명한 역할을 그림을 통해 살펴보자. 우선 리더의 입장에서, 리더는 ISR 내의 팔로워들을 감시하고, 뒤쳐진 팔로워를 ISR 에서 제외한다. 추가적으로, 브로커가 다운되는 경우에 팔로워는 리더로부터 데이터를 가져오지 못하고, 이러한 상황이 일정 시간동안 지속되면 리더는 해당 팔로워가 뒤쳐졌기 때문에 팔로워에게 리더를 넘길 수 없다 판단해 해당 팔로워를 ISR 에서 제외시키는 것이다.
반대로, 팔로워 입장에서 보면 ISR 내의 팔로워는 언제든 리더가 될 수 있어야 하기 때문에 리더와 동일한 데이터를 유지하는 것이 매우 중요하다. 따라서 팔로워는 리더를 계속 바라보며 컨슈머들이 카프카에서 데이터를 가져가는 것과 동일한 방법으로 주기적으로 데이터를 풀링한다. 매우 짧은 주기마다 새로운 데이터를 체크하며 리더와 동기화를 하게 된다.
결국 동일한 ISR 내에서 리더와 팔로워는 데이터 정합성을 위해 각자의 방식으로 서로를 계속 체크하며 Fault-Tolerance 한 메시지 시스템을 제공하는 것이다.
All Down Situation
모든 브로커가 다운되는 상황은 거의 발생하지 않지만, 발생할 수 있는 가능성이 아주 조금이라도 존재하기 때문에 이에 대해 인지하고 대응할 방안을 고려하는 것이 필요하다.
그림을 통해 순서대로 상황을 설명하자면 다음과 같다.
프로듀서가 위와 같이 파란색 메시지를 카프카에 보냈고, Leader 와 두 Follower 모두 메시지를 전달받았다. 하지만 메시지가 전달되자마자 브로커3 이 다운되었다.
다음으로 프로듀서가 초록색 메시지를 보냈고, 위와 마찬가지로 동작하는 리더 / 팔로워에게 모두 메시지가 전달되었다. 하지만 브로커2가 메시지를 받고 바로 다운되었다.
세 번째로 프로듀서가 분홍색 메시지를 보냈고, 리더에게만 전달되었다. 하지만 리더가 동작중이던 브로커1이 바로 다운되면서, 결국 모든 브로커가 다운되었다.
이러한 경우에 대응할 수 있는 방법이 두 가지가 있다.
마지막까지 리더였던 브로커1이 다시 Up 되고 리더가 될 때까지 기다린다.
리더 / 팔로워 상관없이 가장 빨리 Up 이 되는 브로커의 파티션이 리더가 된다.
카프카는 기본 설정으로 2번 방법을 사용한다. 동작 방식을 설명하기 위해, 가장 적은 메시지를 보유한 브로커3 이 가장 먼저 Up 되는 상황을 살펴보자.
파란색 메시지만 저장한 브로커3 이 Up 되고, 새로운 리더가 되었다. 새로운 리더가 된 후 프로듀서가 보라색 메시지를 보냈고, 리더에게 잘 전달되었다.
이후 브로커1 / 브로커2 가 모두 Up 되었고, 자동으로 팔로워로 이들이 연결되면서 리더로부터 데이터를 복제한다. 이 과정에서 결과적으로 초록색, 분홍색 메시지는 손실되었다.
위의 예제에서, 카프카의 설정을 변경함으로써 1번 방법으로 대응할 수도 있다. 1번 방법은 모든 브로커가 다운되는 상황에서도 데이터 손실 가능성이 적기 때문에 좋은 대응방안이 될 수 있다. 하지만 여기에는 조건이 붙는데, 마지막 리더인 브로커1 이 반드시 Up 되어야 하고, 또 가장 먼저 Up 되어야 한다. 그렇게 될 경우 거의 손실 없이 모든 데이터의 복구가 가능하다. 이와 같은 장점이 있는 반면, 최악의 경우 브로커1이 기계적 결함으로 Up 이 되지 않거나 Up 되는 데 오랜 시간이 걸릴 경우 장애 상황인 채로 막연히 기다리게 되는 문제가 있다.
위와 같은 문제로 인해, 일반적으로 빠른 장애 대응이 가능한 2번 방법을 적용하고 데이터의 손실을 감안하는 방법이 효율적일 수 있다. 물론 위와 같이 클러스터 전체가 다운되는 경우는 거의 발생하지 않지만, 앞서 언급했듯 가능성이 있다는 것만으로 대응할 준비는 필요하다.
카프카의 컨슈머가 poll() 을 호출할 때마다, 컨슈머 그룹은 카프카에 저장되어 있지만 아직 읽지 않은 메시지들을 가져와 처리한다. 이렇게 할 수 있는 것은 컨슈머 그룹이 카프카의 메시지를 어디까지 읽었는 지를 저장하고 있기 때문인데, 어디까지 읽었는 지를 Offset 이라는 값으로 저장하게 된다. 이전 포스팅 에서 다뤘듯, 카프카에 저장되는 각 레코드들은 파티션 별로 독립적인 Offset 값을 가지게 되고, 컨슈머 그룹이 파티션 별로 마지막으로 읽은 레코드의 Offset 을 저장함으로써 읽은 메시지와 읽지 않은 메시지를 구분한다.
그러면 컨슈머에 어떤 문제가 발생해 기존에 관리하던 오프셋 정보가 날아간다면? 컨슈머들은 파티션 별로 모든 메시지를 다시 읽고 중복 처리해야 할까?
정답부터 말하자면, 그렇지 않다. 카프카의 컨슈머 그룹은 위와 같은 문제가 발생하는 것을 막기 위해 Offset 을 내부적으로 저장하기도 하지만 카프카 내에 별도로 내부적으로 사용하는 토픽을 생성하고, 그 토픽에 오프셋 정보를 저장하게 되어있다.
위와 같이 오프셋 정보를 카프카의 내부 토픽에 저장하는 것을 Commit 이라 하는데, 카프카에서는 커밋과 관련된 여러 방법을 제공한다.
Commit
위에서 언급했듯, 컨슈머는 내부적으로 오프셋 정보를 저장하고 이를 사용해 읽지 않은 메시지들만 파티션에서 읽어올 수 있다. 하지만 어떤 상황에는 내부적으로 존재하는 정보를 사용할 수 없는 경우가 존재하는데, 다음의 경우에 그러한 문제들이 생길 수 있다.
컨슈머가 갑자기 다운될 경우
컨슈머 그룹에 새로운 컨슈머가 조인할 경우
위의 경우에, 컨슈머 그룹은 기존에 컨슈머 별로 할당된 파티션에 문제가 생긴다. 새로 조인한 컨슈머가 파티션을 배정받지 않아 노는 경우가 생기거나, 기존에 파티션을 배정받아 처리하던 컨슈머가 다운됨으로 인해 해당 파티션을 처리할 컨슈머가 존재하지 않게 된다.
컨슈머 그룹은 이를 해결하기 위해 그룹 내에서 컨슈머들의 리밸런싱을 수행하게 되는데, 이 때 컨슈머들이 기존에 배정받은 파티션과 다른 파티션을 할당받게 될 수 있어 내부적으로 저장한 오프셋 정보를 사용할 수 없게 된다.
카프카에서는 이를 위해 내부 토픽에 오프셋 정보를 저장하고, 오프셋 값을 업데이트하는 것을 커밋이라 부른다. 리밸런스를 거치게 되면 컨슈머들이 기존과 다른 파티션을 할당받을 수 있기 때문에 가장 최근에 커밋된 오프셋 값을 가져와 메시지를 다시 읽는 과정을 수행한다.
커밋은 어플리케이션의 설정에 따라 자동으로 오프셋 정보를 커밋하는 방법과 수동으로 오프셋을 커밋하는 방법이 나눠진다.
자동 커밋
컨슈머 어플리케이션들이 기본적으로 사용하는 자동 커밋 방식은, 설정한 주기에 따라 poll() 을 호출할 때 자동으로 마지막 오프셋을 커밋한다.
컨슈머 옵션 중 enable.auto.commit = true 로 설정하면 자동 커밋 방식을 사용해 오프셋을 관리할 수 있다. 커밋을 하기 위한 주기는 기본적으로는 5초마다 커밋을 하게 되고, 이 주기 또한 auto.commit.interval.ms 값을 조정해 변경이 가능하다.
자동으로 커밋을 하는 방식은 오프셋 관리를 자동으로 하기 때문에 편리한 장점이 있는 반면, 리밸런싱으로 인한 문제가 생길 수 있다는 점을 염두해야 한다.
예를 들어, 5초마다 자동으로 커밋을 하게 어플리케이션을 설정했다고 하자. 매 5초마다 커밋이 발생할텐데 커밋이 발생하고 3초 뒤에 리밸런싱이 이루어진다면 어떻게 될까? 3초동안 처리한 메시지들에 대해서는 커밋이 이루어지지 않아 리밸런싱이 수행된 후 다른 컨슈머에 의해 다시 메시지를 읽고 중복으로 처리하게 될 수 있다.
자동 커밋의 주기를 줄인다고 해도, 중복이 발생하는 메시지의 개수를 줄일 뿐 중복 자체를 없앨 수는 없다. 그러면 이 문제를 해결하기 위해 고려해야 하는 것은 어떤 것이 있을까? 카프카는 이와 같이 메시지의 중복 수신이 발생할 수 있기 때문에 메시지 처리에 있어 멱등성을 생각해야 한다. 중복으로 메시지를 처리하더라도 결과에 변동이 되지 않도록 어플리케이션의 설계를 잘 해야 한다.
수동 커밋
수동 커밋은 자동 커밋과 다르게, 메시지 처리가 완벽하게 이루어지지 않으면 메시지를 읽지 않은 것으로 간주해야 할 경우 사용된다.
예를 들어, 컨슈머가 메시지를 가져와 DB 에 저장하는 상황이라 가정하자. 만약 자동 커밋을 사용한다면, DB 에 저장하는 로직이 실패할 경우에도 메시지의 오프셋은 커밋되었기 때문에 메시지의 손실이 발생할 수 있다. 이러한 경우를 방지하기 위해서, DB 에 저장되는 로직이 성공한 것을 확인한 후 메시지의 오프셋을 커밋해 메시지가 손실되지 않고 처리될 수 있도록 해야 한다.
일반적으로는 위와 같이 메시지 처리의 결과에 따라 오프셋 커밋을 결정할 때 사용하는 것이 수동 커밋인데, 이 또한 자동 커밋 방식과 마찬가지로 메시지의 중복이 발생할 수 있다. 위와 같은 DB 저장 오류 시, 해당 메시지부터 다시 읽어와 처리를 수행하게 될텐데 해당 메시지 이후의 메시지들은 정상적으로 DB 에 저장되었다고 하자. 그러면 결국 오류가 발생한 메시지 외의 다른 메시지들은 중복으로 DB 에 저장될 것이다.
결국 어떤 커밋 방식을 사용한다 하더라도 메시지가 중복되는 것은 피할 수 없는 문제이다. 이는 카프카에서 기본적으로 Exactly-Once 방식이 아니라 At-Least-Once 방식을 채용하고 있기 때문인데, 중복은 발생할 수 있지만 손실은 발생하지 않는다는 원칙이다.
카프카에서도 Exactly-Once 를 사용할 수 있는 방식은 있지만 기본적으로는, 메시지의 중복을 처리하는 것은 결국 카프카를 사용하는 개발자의 몫이고 이 문제의 해결을 위해 많은 고민을 필요로 한다.
이 포스팅의 주요 목적은 카프카에서 핵심적인 역할을 하는 파티션에 대해 공부하는 것이다. 파티션에 대해 이해를 해야 카프카의 구조나 동작에 대해 빠르게 이해할 수 있고, 올바르게 사용할 수 있다.
Events, Streams, and Topics
파티션에 대해 공부하기 전에, 카프카에서 사용되는 몇 가지 개념과 그것들이 파티션과 어떻게 연관이 있는지를 알아보자.
Events
이벤트란, 과거에 일어난 사실을 뜻한다. 이벤트는 발생함으로 인해 변화된 상태를 가지고 시스템 사이를 오가는, 불변하는 데이터이다.
Streams
이벤트 스트림이란, 관련된 이벤트들을 뜻한다.
Topics
이벤트 스트림이 카프카에서는 토픽이란 이름으로 저장된다. 카프카의 세계에서는 토픽이 구체화된 이벤트 스트림을 뜻한다. 토픽은 연관된 이벤트들을 묶어 영속화하는데, 이는 데이터베이스의 테이블이나 파일 시스템의 폴더들에 비유할 수 있다.
토픽은 카프카에서 Producer 와 Consumer 를 분리하는 중요한 컨셉이다. Producer 는 카프카의 토픽에 메시지를 저장 (Push) 하고 Consumer 는 저장된 메시지를 읽어 (Pull) 온다. 하나의 토픽에 여러 Producer / Consumer 가 존재할 수 있다.
위의 개념들은 아래의 그림으로도 설명이 가능하다. Event 가 관련된 것들끼리 모여 Stream 을 이루게 되고, 이것이 카프카에 저장될 때 Topic 의 이름으로 저장된다.
Partitions
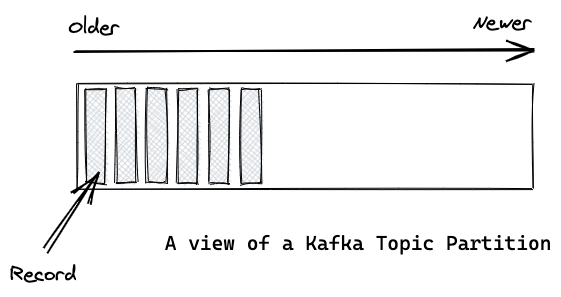
이제 본격적으로, 파티션에 대한 내용을 다루려 한다. 위에서 설명한 카프카의 토픽들은 여러 파티션으로 나눠진다. 토픽이 카프카에서 일종의 논리적인 개념이라면, 파티션은 토픽에 속한 레코드를 실제 저장소에 저장하는 가장 작은 단위이다. 각각의 파티션은 Append-Only 방식으로 기록되는 하나의 로그 파일이다.
참고한 포스팅에서 Record 와 Message 는 위의 그림에서 표현하는 것과 같이 파티션 내에 저장되는 메시지라는 의미로 사용되었다.
Offsets and the ordering of messages
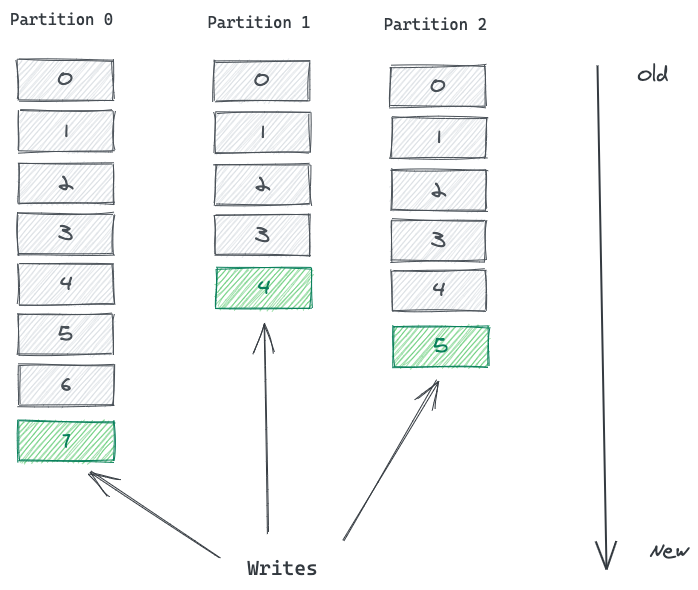
파티션의 레코드는 각각이 Offset 이라 불리는, 파티션 내에서 고유한 레코드의 순서를 의미하는 식별자 정보를 가진다. 하지만 카프카는 일반적으로 메시지의 순서를 보장하지 않는다. 위에서 각각의 파티션은 Append-Only 방식으로 레코드를 기록한다 했고, 내부적으로 Offset 이라는 정보를 사용하는데 왜 메시지의 순서가 보장되지 않는 것일까? 자세한 내용은 아래의 내용을 보면 이해할 수 있고, 간단하게는 파티션 간에는 순서가 보장되지 않으므로 결국 메시지의 순서가 보장되지 않는다 할 수 있다.
Offset 정보는 카프카에 의해서 관리되고, 값이 계속 증가하며 불변하는 숫자 정보이다. 레코드가 파티션에 쓰여질 때 항상 기록의 맨 뒤에 쓰여지고, 다음 순서의 Offset 값을 갖게 된다. 오프셋은 파티션에서 레코드를 읽고 사용하는 Consumer 에게 특히 유용한데, 자세한 내용은 뒤에서 설명하겠다.
아래의 그림은 세 개의 파티션을 갖는 토픽을 보여준다. 레코드는 각 파티션의 마지막에 추가된다. 아래에서 볼 수 있듯, 메시지는 파티션 내에서는 유의미한 순서를 가지고 이를 보장하지만, 파티션 간에는 보장되지 않는다.
Partitions are the way that Kafka provides Scalability
카프카의 클러스터는 브로커라 불리는 하나 혹은 그 이상의 서버들로 이루어지는데, 각각의 브로커는 전체 클러스터에 속한 레코드의 서브셋을 가진다.
카프카는 토픽의 파티션들을 여러 브로커에 배포하는데 이로 인해 얻을 수 있는 다음과 같은 이점들이 있다.
만약 카프카가 한 토픽의 모든 파티션을 하나의 브로커에 넣을 경우, 해당 토픽의 확장성은 브로커의 I/O 처리량에 의해 제약된다. 파티션들을 여러 브로커에 나눔으로써, 하나의 토픽은 수평적으로 확장될 수 있고 이로 인해 브로커의 처리 능력보다 더 큰 성능을 제공할 수 있게 된다.
토픽은 여러 Consumer 에 의해 동시에 처리될 수 있다. 단일 브로커에서 모든 파티션을 제공하면 지원할 수 있는 Consumer 수가 제약되는데, 여러 브로커에서 파티션을 나누어 제공함으로써 더 많은 Consumer 들이 동시에 토픽의 메시지를 처리할 수 있게 된다.
동일한 Consumer 의 여러 인스턴스가 서로 다른 브로커에 있는 파티션에 접속함으로써 매우 높은 메시지 처리량을 가능케 한다. 각 Consumer 인스턴스는 하나의 파티션에서 메시지를 제공받고, 각각의 레코드는 명확한 처리 담당자가 존재함을 보장할 수 있다.
Partitions are the way that Kafka provides Redundancy
카프카는 여러 브로커에 동일 파티션의 복사본을 두 개 이상 유지한다. 이러한 복사본을 Replica 라 하는데, 브로커에 장애가 발생했을 때에도 장애가 발생한 브로커가 소유한 파티션의 복사본을 통해 컨슈머에게 지속적으로 메시지를 제공할 수 있게 한다.
파티션 복제는 다소 복잡해, 지금은 파티션에 대한 정리에 집중하고 다음 포스팅에서 Replica 를 주제로 다시 정리하려 한다.
Writing Records to Partitions
위에서 파티션이 무엇인지, 어떤 방식으로 사용되고 어떤 장점을 갖는지를 정리해 봤다. 그러면 파티션에 레코드를 어떻게 작성하고 어떻게 읽을까? 우선 레코드의 작성법부터 살펴보자. Producer 는 각각의 레코드가 어떤 파티션에 쓰여질 것인지를 어떻게 결정할까? 다음과 같이 세 가지의 방법이 존재한다.
Using a Partition Key
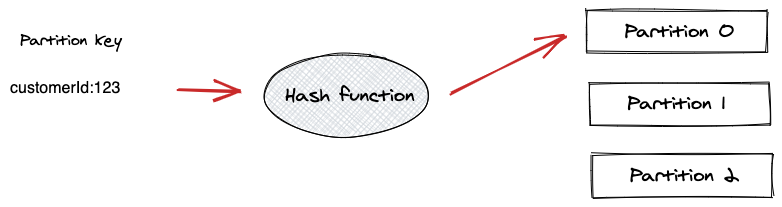
Producer 는 파티션 키를 사용해서 특정한 파티션에 메시지를 전달할 수 있다. 파티션 키는 Application Context 에서 파생될 수 있는 어떤 값이든 될 수 있다. 고유한 장비의 ID 나 사용자의 ID 는 좋은 파티션 키를 만들 수 있다.
기본적으로 파티션 키는 해싱 함수를 통해 전달되고 해싱 함수는 동일한 키를 갖는 모든 레코드들이 동일한 파티션에 도착하는 것을 보장한다. 파티션 키를 지정할 경우 다음 그림과 같이 관련된 이벤트를 동일한 파티션에 유지함으로써 전달된 순서가 그대로 유지되는 것을 보장할 수 있다.
파티션 키를 사용한 방법이 위와 같이 발생한 이벤트의 순서를 보장할 수 있다는 장점을 가진 반면, 키가 제대로 분산되지 않는 경우 특정 브로커만 메시지를 받는 단점도 존재한다.
예를 들어, 고객의 ID 가 파티션 키로 사용되고 어떤 고객이 트래픽의 90% 를 생성한다 하자. 이 경우, 대부분의 어플리케이션 수행 동안 하나의 파티션에서 90% 의 트래픽을 감당하게 된다. 전체 트래픽이 작은 경우는 이를 무시할 수 있지만, 만약 트래픽이 많은 경우에 이와 같은 상황이 발생한다면 이는 종종 브로커의 장애로 이어질 수 있다.
이런 이유로, 파티션 키를 사용하고자 한다면 이들이 잘 분산되는 지를 확인할 필요가 있다.
Allowing Kafka to decide the partition
Producer 가 레코드를 생성할 때 파티션 키를 명시하지 않으면, Kafka 는 Round-Robin 방식을 사용해 파티션을 배정한다. 이러한 레코드들은 해당 토픽의 파티션들에 고루 분배된다.
그러나, 파티션 키가 사용되지 않을 경우 레코드들의 순서는 보장되지 않는다. 위에서 파티션 키를 사용할 경우와 반대로, 순서가 보장되지 않는 대신 파티션의 분배는 고루 이루어진다.
Writing a customer partitioner
특정 상황에서는, Producer 가 서로 다른 비즈니스 규칙을 사용한 자체 파티셔너 구현을 사용할 수도 있다.
파티션 분배를 위해 어떤 전략을 사용하는 것이 좋을 지는 항상 명확하지 않다. 메시지 간 순서가 반드시 보장되어야 할 수도 있고, 순서와 관계없이 이벤트의 처리가 가능할 수 있다.
무엇이 좋고 나쁘다의 개념보다는, 각각의 방법이 이러한 장단점이 있으니 상황에 따라 유의해 사용하자. 로 생각을 하면 좋을 것 같다.
Reading records from partitions
Producer 가 레코드 생성할 때 어떤 파티션에 이를 저장할 지를 위에서 봤으니, 이제는 Consumer 가 파티션에서 레코드를 어떻게 읽는 지를 알아볼 차례이다.
보통의 pub/sub 모델과는 달리, Kafka 는 메시지를 Consumer 에 전달 (push) 하지 않는다. 대신, Consumer 가 카프카의 파티션으로부터 메시지를 읽어 (pull) 가야 한다. 컨슈머는 브로커의 파티션과 연결해, 메시지들이 쓰여진 순서대로 메시지를 읽는다.
메시지의 Offset 은 Consumer 측의 커서와 같이 동작한다. Consumer 는 메시지의 오프셋을 추적하고 이를 통해 이미 소비한 메시지를 저장한다. 메시지를 읽고 난 뒤 Consumer 는 파티션의 다음 Offset 으로 커서를 이동하고, 다시 메시지를 읽고, .. 이 과정을 계속 반복한다.
각 파티션에서 마지막으로 소비된 메시지의 Offset 을 기억함으로써 Consumer 는 어떤 시점에 파티션의 어떤 위치에서 재시작할 수 있다. 이를 통해 Consumer 는 장애를 복구한 뒤 메시지 소비를 재시작할 수 있다.
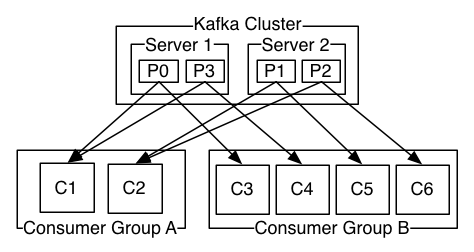
파티션은 하나 혹은 그 이상의 Consumer 들로부터 소비될 수 있고, 각각은 서로 다른 Offset 을 가지고 메시지를 읽을 수 있다. 카프카는 Consumer Group 이라는 개념을 사용하는데, 이는 어떤 토픽을 소비하는 Consumer 들을 그룹으로 묶은 것이다. 동일한 Consumer Group 에 있는 Consumer 들은 동일한 Group-Id 를 부여받는다. 파티션 내의 메시지는 그룹 내의 Consumer 중 하나에 의해서만 소비되는 것을 보장한다.
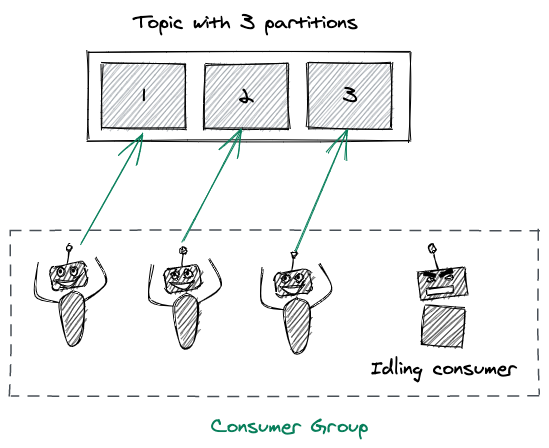
아래의 그림은 Consumer 그룹 내에서 파티션들이 어떻게 소비되는 지를 보여준다.
Consumer Group 은 Consumer 들이 병렬적으로 메시지를 소비할 수 있도록 한다. 병렬 처리를 가능케 함으로써 처리량은 매우 높아지지만, 그룹의 Maximum Parallelism 은 토픽의 파티션 개수와 동일하다.
예를 들어, N 개의 파티션이 존재하는 토픽에 N + 1 개의 Consumer 가 있는 경우, N 개의 Consumer 들은 파티션을 각각 배정받지만 남은 Consumer 는 다른 Consumer 가 장애가 발생하지 않는 한, Idle 상태로 파티션에 배정되기를 기다리게 된다. 이는 Hot Failover 를 구현하는 좋은 전략이 될 수 있다.
아래의 그림은 위의 예시를 표현한 것이다.
여기서 중요한 것은, Consumer 의 개수가 토픽의 병렬성 정도를 결정하지 않고, 결정하는 것은 파티션의 개수라는 것이다. 하지만 파티션을 늘리는 것이 항상 장점으로 작용하지는 않는다. 파티션의 개수에 따른 이점과 문제점은 추후에 다시 정리해보도록 하겠다.
자바를 사용하며 많은 어노테이션들을 코드에 적용하고 사용해 왔지만 정작 어노테이션이 어떤 의미를 갖는 것인지, 어떻게 사용해야 하고 어떤 식으로 개발자에게 도움을 줄 수 있는지를 몰라 이에 대해 정리를 해보려 한다.
우선 어노테이션의 사전적인 의미는 "주석" 이다. 일반적으로 생각하는 주석의 의미와는 사뭇 다른데, 보통 코드에서 주석의 역할은 소스 코드로 표현하기 어려운 개발자의 의도 등을 설명하기 위해 사용되는 것으로 알고 있다. 반면 어노테이션은 자바 코드에 추가될 수 있는 메타데이터라는 의미를 갖는다.
어노테이션의 특징
컴파일러에게 코드 문법 에러를 체크할 수 있도록 정보를 제공
소프트웨어 개발 툴이 빌드나 배치 시 자동으로 코드를 생성할 수 있도록 정보 제공
어노테이션을 만들 때는 용도를 명확하게 해야 한다.
소스 상에서만 유지할 것인지
컴파일된 클래스에서도 유지할 것인지
런타임 시에도 유지할 것인지
Built-In Annotation
@Override
메소드가 오버라이드 됐는지 검증
부모 클래스나 구현해야 할 인터페이스에서 해당 메소드를 찾을 수 없을 경우 오류 발생
@Deprecated
메소드를 사용하지 않도록 유도
만약 위 어노테이션이 붙은 메소드를 사용할 경우 컴파일 시 경고를 발생
@SuppresWarnings
컴파일 경고를 무시
@SafeVarargs
제너릭과 같은 가변 인자를 사용할 때 경고를 무시 (Java 7 이상)
@FunctionalInterface
람다 함수 등을 위한 인터페이스를 지정
메소드가 없거나 두 개 이상일 경우 컴파일 오류 발생 (Java 8 이상)
Meta Annotations
위의 Built-In Annotation 같은 경우는, 기본적으로 자바에서 제공하는 어노테이션이다. 자바에서는 이 외에도 Meta Annotation 이라는 것을 지원하는데 이들을 활용해 커스텀 어노테이션을 만들고 사용하는 것 또한 지원한다.
@Inherited // 상속
@Documented // 문서에 정보가 표현
@Retention(RetentionPolicy.RUNTIME) // 컴파일 이후에도 JVM에 의해서 참조가 가능합니다
@Retention(RetentionPolicy.CLASS) // Compiler가 클래스를 참조할 때까지 유효합니다
@Retention(RetentionPolicy.SOURCE) // 컴파일 이후 사라집니다
@Target({
ElementType.PACKAGE, // 패키지 선언시
ElementType.TYPE, // 타입 선언시
ElementType.CONSTRUCTOR, // 생성자 선언시
ElementType.FIELD, // 멤버 변수 선언시
ElementType.METHOD, // 메소드 선언시
ElementType.ANNOTATION_TYPE, // 어노테이션 타입 선언시
ElementType.LOCAL_VARIABLE, // 지역 변수 선언시
ElementType.PARAMETER, // 매개 변수 선언시
ElementType.TYPE_PARAMETER, // 매개 변수 타입 선언시
ElementType.TYPE_USE // 타입 사용시
})
public @interface NesoyAnnotation{
/* enum 타입을 선언할 수 있습니다. */
public enum Quality {
BAD, GOOD, VERYGOOD
}
/* String은 기본 자료형은 아니지만 사용 가능합니다. */
String value() default "NesoyAnnotation : Default String Value";
/* 배열 형태로도 사용할 수 있습니다. */
int[] values();
/* enum 형태를 사용하는 방법입니다. */
Quality quality() default Quality.GOOD;
}
JDBC (Java DataBase Conectivity) 는 DB 제작사에 구애받지 않고 RDBMS 에 접근할 수 있도록 표준 API 셋을 제공한다. DB 에 SQL 문을 실행하는 API 를 제공하는 것이 JDBC 의 주용도지만, JDBC 를 있는 그대로 사용하려면 직접 DB 리소스를 관리하면서 예외도 명시적으로 처리해야 해 개발에 있어 번거롭다. 스프링은 JDBC 를 추상화한 프레임워크인 JDBC Template 을 지원하는데 이를 통해 여러 유형의 JDBC 작업을 템플릿 메소드로 묶어서 제공한다. 전체 작업 흐름은 템플릿 메소드가 각각 알아서 관장하고 개발자는 원하는 작업을 오버라이딩해 사용할 수 있어 개발자에게 편의성을 제공한다.
스프링 ORM
JDBC 자체만으로는 필요한 요건을 충족하기 어렵고 개발 편의성을 더 추구할 경우 더 고수준의 추상화를 지원하는 스프링 ORM (Object-Relational Mapping) 솔루션을 사용할 수 있다. 스프링은 하이버네이트, JDO, iBatis, JPA (Java Persistence API) 등의 유명한 ORM 프레임워크를 지원한다. ORM 프레임워크는 매핑 메타데이터에 따라 객체를 저장하는 기술이다. 객체를 저장하는 SQL 문은 런타임에 생성되므로 특정 DB 에 있는 기능을 불러쓰거나 직접 SQL 문을 튜닝하지 않는 이상 DB 에 특정한 SQL 을 작성할 필요가 없다. 결과적으로 DB 에 독립적인 어플리케이션을 개발할 수 있고, 차후 다른 DB 로 마이그레이션하기 쉽다.
Hibernate 는 자바 커뮤니티에서 널리 알려진 고성능 오픈 소스 ORM 프레임워크로, JDBC 호환 DB 는 대부분 지원하며 DB 별 방언 (Dialect) 을 이용해 액세스할 수 있다. ORM 기본 외에 Caching, Cascading, Lazy Loading 과 같은 고급 기능들을 제공하고 HQL (Hibernate Query Language) 을 이용하면 단순하면서 강력한 객체 쿼리를 수행할 수 있다.
JDBC 를 직접 사용할 경우 문제점
자동차 정보를 등록하는 애플리케이션을 개발하려 한다. 자동차 레코드를 CRUD 하는 게 주된 기능이고, 레코드는 RDBMS 에 저장해 JDBC 로 접근한다. 다음은 자동차를 나타내는 Vehicle 클래스이다.
public class Vehicle {
private String vehicleNo;
private String color;
private int wheel;
private int seat;
// Constructor, Setter, Getter ...
}
DAO 디자인 패턴
서로 다른 종류의 로직 (Presentation Logic, Business Logic, Data Access Logic 등) 을 하나의 거대한 모듈에 뒤섞는 설계상 실수를 저지르는 경우가 왕왕 있다. 이렇게 하면 모듈 간에 단단하게 결합돼 재사용성과 유지 보수성이 현저히 떨어지게 된다. DAO 는 이런 문제를 해결하고자 데이터 액세스 로직을 표현하고, 비즈니스 로직과는 분리해 DAO 라는 독립적인 모듈에 데이터 액세스 로직을 담아 캡슐화한 패턴이다.
자동차 등록 애플리케이션에서도 자동차 레코드를 CRUD 하는 각종 데이터 액세스 작업을 추상화할 수 있다. 다음과 같이 인터페이스로 선언하면 여러 DAO 구현 기술을 적용할 수 있다.
JDBC API 는 대부분 java.sql.SQLException 예외를 던지도록 설계됐지만 이 인터페이스의 유일한 의의는 데이터 액세스 작업의 추상화이므로 구현 기술에 의존해서는 안 된다. JDBC 에 특정한 SQLException 을 던지는 것은 취지에 어긋나므로 보통 DAO 구현체에서는 RuntimeException 의 하위 예외 (직접 구현한 Exception 하위 클래스나 제네릭형) 로 감싼다.
JDBC 로 DAO 구현하기
JDBC 를 사용해 DB 데이터에 액세스하려면 DAO 구현 클래스 (JdbcVehicleDao) 가 필요하고 DB 에 SQL 문을 실행하려면 드라이버 클래스명, DB URL, 유저명, 패스워드를 지정해 DB 에 접속해야 한다. 하지만 미리 구성된 javax.sql.DataSource 객체를 이용하면 접속 정보를 자세히 몰라도 DB 에 접속할 수 있다.
public class JdbcVehicleDao implements VehicleDao {
private static final String INSERT_SQL =
"INSERT INTO VEHICLE (COLOR, WHEEL, SEAT, VEHICLE_NO) VALUES (?, ?, ?, ?)";
private static final String UPDATE_SQL =
"UPDATE VEHICLE SET COLOR = ?, WHEEL = ?, SEAT = ? WHERE VEHICLE_NO = ?";
private static final String SELECT_ALL_SQL =
"SELECT * FROM VEHICLE";
private static final String SELECT_ONE_SQL =
"SELECT * FROM VEHICLE WHERE VEHICLE_NO = ?";
private static final String DELETE_SQL =
"DELETE FROM VEHICLE WHERE VEHICLE_NO = ?";
@Autowired
private final DataSource dataSource;
@Override
public void insert(Vehicle vehicle) {
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(INSERT_SQL)){
prepareStatement(ps, vehicle);
ps.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Override
public void insert(Collection<Vehicle> vehicle) {
vehicles.forEach(this::insert);
}
@Override
public Vehicle findByVehicleNo(String vehicleNo) {
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(SELECT_ONE_SQL)) {
ps.setString(1, vehicleNo);
Vehicle vehicle = null;
try (ResultSet rs = ps.executeQuery()) {
if (rs.next()) {
vehicle = toVehicle(rs);
}
}
return vehicle;
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Override
public List<Vehicle> findAll() {
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(SELECT_ALL_SQL);
ResultSet rs = ps.executeQuery()) {
List<Vehicle> vehicles = new ArrayList<>();
while (rs.next()) {
vehicles.add(toVehicle(rs));
}
return vehicles;
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
private Vehicle toVehicle(ResultSet rs) throws SQLException {
return new Vehicle(rs.getString("VEHICLE_NO"),
rs.getString("COLOR"),
rs.getInt("WHEEL"),
rs.getInt("SEAT"));
}
private void prepareStatement(PreparedStatement ps, Vehicle vehicle)
throws SQLException {
ps.setString(1, vehicle.getColor());
ps.setInt(2, vehicle.getWheel());
ps.setInt(3, vehicle.getSeat());
ps.setString(4, vehicle.getVehicleNo());
}
@Override
public void update(Vehicle vehicle) { ... }
@Override
public void delete(Vehicle vehicle) { ... }
}
자동차 레코드의 등록 작업은 전형적인 JDBC 로 데이터를 수정하는 시나리오이다. insert() 를 호출할 때마다 데이터 소스에서 접속 객체를 얻어와 SQL 문을 실행한다. try-with-resources 메커니즘을 적용한 위 코드는 사용을 마친 리소스를 자동으로 닫는다. try-with-resources 블록을 사용하지 않으면 사용한 리소스를 닫았는지 잘 기억해야 하고 혹여 착오가 있으면 메모리 누수로 이어질 가능성이 있다.
스프링 데이터 소스 구성하기
javax.sql.DataSource 는 Connection 인스턴스를 생성하는 표준 인터페이스로, JDBC 명세에 규정되어 있다. 데이터 소스 인터페이스는 여러 구현체가 있는데, 그중 HikariCP 와 Apache Commons 가 가장 잘 알려진 오픈 소스 구현체이다. 종류는 다양하지만 모두 DataSource 라는 공통 인터페이스를 구현하기 때문에 다른 걸로 바꿔쓰기 쉽다. 스프링 역시 간단하면서 기능은 막강한 데이터 소스 구현체를 지원한다. 그중 요청을 할 때마다 접속을 새로 여는 DriverManagerDataSource 는 가장 간단한 구현체이다.
@Configuration
public class VehicleConfiguration {
@Bean
public VehicleDao vehicleDao() {
return new JdbcVehicleDao(dataSource());
}
@Bean
public DataSource dataSource() {
DrvierManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName(ClientDriver.class.getName());
dataSource.setUrl("jdbc_url");
dataSource.setUserName("ds_user");
dataSource.setPassword("ds_pwd");
return dataSource;
}
}
DAO 실행하기
이제 새 자동차 레코드를 DB 에 등록하는 DAO 를 테스트한다. 별 문제 없으면 DB 에 등록한 자동차 정보가 곧바로 출력될 것이다.
public class Main {
public static void main(String[] args) {
ApplicationContext context =
new AnnotationConfigApplicationContext(VehicleConfiguration.class);
VehicleDao vehicleDao = context.getBean(VehicleDao.class);
Vehicle vehicle = new Vehicle("TEM0001", "RED", 4, 4);
vehicleDao.insert(vehicle);
vehicle = vehicleDao.findByVehicleNo("TEM0001");
System.out.println(vehicle);
}
}
이렇게 JDBC 를 직접 사용해 DAO 를 구현할 수 있지만, 보다시피 비슷하게 생긴 코드가 DB 작업을 처리할 때마다 반복되는 걸 확인할 수 있다. 이처럼 코드가 계속 중복되면 DAO 메소드는 장황해지고 가독성은 떨어지게 된다.
다음에 정리할 내용부터, 위와 같이 JDBC 를 직접 사용했을 때의 문제를 해결하기 위한 방법들을 제공한다. JDBC Template 부터 ORM 프레임워크까지, 이 방법들을 통해 데이터 액세스 로직보다는 비즈니스 로직에 집중하는 개발 방법을 확인할 수 있다.
REST 에 대한 설명은 이전 포스팅 에서 정리했으니, 추가적인 설명은 하지 않고 스프링의 REST 에 대해 살펴보려 한다.
1. REST 서비스로 XML 발행하기
스프링에서 REST 서비스를 설계할 때는 두 가지 가능성을 고려해야 한다. 하나는 애플리케이션 데이터 자체를 REST 서비스로 발행하는 것이고, 다른 하나는 애플리케이션에서 쓸 데이터를 서드파티 REST 서비스에서 가져오는 것이다. 여기서는 전자의 경우를 먼저 설명하고 후자의 경우는 뒤에서 다시 설명할 것이다.
스프링 MVC 에서 애플리케이션 데이터를 REST 서비스로 발행하기 위한 주된 방법은 @RequestMapping 과 @PathVariable 두 어노테이션이다. 이들을 적절히 사용함으로써 스프링 MVC 핸들러 메소드가 자신이 조회한 데이터를 REST 서비스로 발행하도록 하는 것이다. 이 외에도 스프링에는 REST 서비스의 페이로드를 생성하는 다양한 매커니즘이 있다.
웹 애플리케이션에서 데이터를 REST 서비스로 발행하는 (웹 서비스의 기술 용어로 이를 '엔드포인트를 생성한다' 라고 표현한다) 작업은 3장의 스프링 MVC 와 밀접한 연관을 갖는다. 스프링 MVC 에서는 핸들러 메소드에 @RequestMapping 어노테이션을 붙임으로써 액세스 지점을 정의했는데, REST 서비스의 엔드포인트도 이와 같이 정의하는 것이 좋다.
MarshallingView 로 XML 만들기
다음은 스프링 MVC 컨트롤러의 핸들러 메소드에 REST 서비스의 엔드포인트를 정의한 코드이다.
@Controller
public class RestMemberController {
private final MemberService memberService;
// Constructor
@RequestMapping("/members")
public String getRestMembers(Model model) {
Members members = memberService.findAll();
model.addAttribute("members", members);
return "membertemplate";
}
}
핸들러 메소드인 getRestMembers() 에 @RequestMapping("/members") 를 붙였기 때문에 REST 서비스 엔드포인트는 "호스트명/[애플리케이션명]/members" URI 로 접근할 수 있고, 마지막 줄에서 membertemplate 논리 뷰로 실행의 흐름을 넘기고 있다. membertemplate 은 구성 클래스에서 다음과 같이 정의할 필요가 있다.
public class CourtRestConfiguration {
@Bean
public View membertemplate() {
return new MarshallingView(jaxb2Marshaller());
}
@Bean
public Marshaller jaxb2Marshaller() {
Jaxb2Marshaller marshaller = new Jaxb2Marshaller();
marshaller.setClassesToBeBound(Members.class, Member.class);
return marshaller;
}
@Bean
public ViewResolver viewResolver() {
return new BeanNameViewResolver();
}
}
membertemplate 뷰는 MarshallingView 형으로 정의한다. MarshallingView 는 마샬러를 이용해 응답을 렌더링하는 범용 클래스이다. 마샬링 (Marshalling) 이란, 간단히 말해 메모리에 있는 객체를 특정한 데이터 형식으로 변환하는 과정이다. 위 예제에서 마샬러는 Member, Members 객체를 XML 형식으로 바꾸는 일을 한다.
마샬러 역시 구성이 필요하다. 위에서는 Jaxb2Marshaller 를 사용했다. Jaxb2Marshaller 를 구성할 때는 classesToBeBound, contextPath 둘 중 하나의 프로퍼티를 설정한다. classesToBeBound 는 XML 로 변환할 대상 클래스를 의미한다. 다음과 같이 마샬링할 클래스에 @XmlRootElement 어노테이션을 붙여 설정할 수 있다.
@XmlRootElement
public class Member {
...
}
@XmlRootElement
@XmlAccessorType(XmlAccessType.FIELD)
public class Members {
@XmlElement(name = "member")
private List<Member> members = new ArrayList<>();
...
}
위의 Member 클래스에 붙인 @XmlRootElement 는 Jaxb2Marshaller 가 클래스 필드를 자동으로 감지해 XML 데이터로 바꾸도록 지시한다.
정리하자면, "http://{호스트명}/{애플리케이션명}/members.xml" 형식의 URL 로 접속하면 담당하는 핸들러가 Members 객체를 생성해 이를 membertemplate 논리 뷰로 넘긴다. 마지막 뷰에 정의한 내용에 따라 마샬러를 이용해 Members 객체를 XML 페이로드로 바꾼 후 REST 서비스를 요청한 클라이언트에게 돌려준다.
여기서 예시한 대로 REST 서비스의 엔드포인트를 잘 보면 ".xml" 이라는 확장자로 끝난다. 확장자를 다른 걸로 바꾸거나 아예 빼고 접속할 경우, 이 REST 서비스는 전혀 동작하지 않는다. 이런 로직은 뷰를 해석하는 스프링 MVC 와 직접 연관된 것으로 REST 서비스 자체와는 무관하다.
이 핸들러 메소드에 연결된 뷰는 기본적으로 XML 을 반환하므로 .xml 확장자를 쓸 경우에만 동작하고, 이런 식으로 동일한 핸들러 메소드는 엔드포인트에 따라 여러 뷰를 지원할 수 있다. 요청에 따라 어떤 뷰를 제공할 것인지는 스프링 MVC 의 Content Negotiation 과정에 따라 결정되며, 이 내용은 이전 포스팅 에 정리해 두었다.
@ResponseBody 로 XML 만들기
MarshallingView 로 XML 파일을 생성하는 건 결과 데이터를 보여주는 여러 방법 중 하나에 불과하다. 같은 데이터를 다양한 표현형으로 나타내기 위해서는 그때마다 뷰를 하나씩 추가해야 하기 때문에 상당히 불편할 것이다. 이럴 때 스프링 MVC 의 HttpMessageConverter 를 이용하면 유저가 요청한 표현형으로 객체를 손쉽게 변환할 수 있다.
@Controller
public class RestMemberController {
@ReqeustMapping("/members")
@ResponseBody
public Members getRestMembers() { ... }
}
getRestMembers() 에 붙인 @ResponseBody 는 메소드 실행 결과를 응답의 본문으로 취급하겠다고 스프링 MVC 에게 밝히는 것이다. XML 형식으로 보려면 스프링 Jaxb2RootElementHttpMessageConverter 클래스가 마샬링을 수행한다. 이처럼 핸들러 메소드에 @ResponseBody 를 붙이면 뷰 이름을 전달하지 않고 Members 객체를 반환하는 것으로 XML 데이터를 만들 수 있다.
스프링 4부터는 일일이 메소드에 @ResponseBody 를 붙이지 않고 컨트롤러 클래스에 @Controller 대신 @RestController 를 붙임으로써 위와 같은 효과를 얻을 수 있다.
이와 같이 변경하고 나면 구성 클래스에서 기존에 작성했던 MarshallingView, Jaxb2Marshaller 등의 마샬러는 따로 설정을 하지 않아도 된다.
@PathVariable 로 결과 거르기
REST 서비스는 응답 페이로드의 양을 제한하거나 필터링할 의도로 요청 매개변수를 넣는 것이 일반적이다. 예를 들어, "http://{호스트명}/{어플리케이션명}/member/353" 으로 요청하면 353번 회원 정보, "http://{호스트명}/{어플리케이션명}/reservations/2010-07-07" 으로 요청하면 2010년 7월 7일 예약 내역만 추릴 수 있다.
스프링에서 REST 서비스를 구성할 때는, 다음과 같이 핸들러 메소드의 입력 매개변수에 @PathVariable 을 붙여 메소드 내부에서 사용할 수 있다.
@RestController
public class RestMemberController {
@RequestMapping("/member/{memberId}")
public Member getMember(@PathVariable("memberId") long memberId) { ... }
}
{} 표기법 대신 와일드카드 문자(*) 로 REST 엔드포인트를 나타내는 방법도 있다. REST 를 설계하는 사람들은 대개 표현적인 URL 을 사용하거나, SEO (Search Engine Optimization) 기법을 응용해 조금이라도 검색 엔진에 친화적인 REST URL 을 선호한다. 다음은 와일드카드 표기법을 사용해 REST 서비스를 선언한 코드이다.
@RequestMapping("/member/*/{memberId}")
public Member getMember(@PathVariable("memberId") long memberId) { ... }
와일드카드를 추가해도 REST 서비스의 본연의 기능에는 어떤 영향도 없지만 /member/John+Smith/353, /member/Mary+Jones/353 같은 형식의 URL 로 요청할 수 있으면 유저 가독성이나 SEO 측면에서 효과를 기대할 수 있다.
REST 엔드포인트 핸들러 메소드에서는 다음과 같이 데이터를 바인딩할 수도 있다.
@InitBinder
public void initBinder(WebDataBinder binder) {
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
binder.registerCustomEditor(Date.class, new CustomDateEditor(dateFormat, flase));
}
@RequestMapping("/reservations/{date}")
public void getReservation(@PathVariable("date" Date resDate) { ... }
이와 같이 정의하면, "http://{호스트명}/{어플리케이션명}/reservations/2010-07-07" 을 요청할 경우, getReservation() 메소드가 2010-07-07 값을 꺼내 resDate 변수에 할당하고 이 값을 이용해 REST 웹 서비스 페이로드를 필터링할 수 있다.
ResponseEntity 로 클라이언트에게 알리기
Member 인스턴스를 하나만 조회하는 엔드포인트의 결과는 올바른 회원 정보를 반환하든지, 아니면 무엇도 반환하지 않든지 둘 중 하나의 결과를 갖는다. 어느 쪽이든 요청한 클라이언트 입장에서는 정상 처리를 의미하는 HTTP 응답 코드 200 을 받게 될 것이다. 하지만 리소스가 없으면 없다는 사실을 있는 그대로 알리는 차원에서, "NOT FOUND" 에 해당하는 응답 코드 404 를 반환하는 것이 맞다.
@RequestMapping("/member/{memberId}")
public ResponseEntity<Member> getMember(@PathVariable("memberId") long memberId) {
Member member = memberService.find(memberId);
if (member == null) {
return new ResponseEntity(HttpStatus.NOT_FOUND);
} else {
return new ResponseEntity<>(member, HttpStatus.OK);
}
}
스프링 MVC 에서 ResponseEntity 는 응답 결과의 본문을 HTTP 상태 코드와 함께 집어넣은 래퍼 클래스이다. 이제 getMember() 메소드는 요청에 따른 결과가 존재하면 응답 코드 200 과 결과를, 없으면 응답 코드 400 을 반환하게 된다.
2. REST 서비스로 JSON 발행하기
AJAX 를 고려한 스프링 애플리케이션의 REST 서비스는 브라우저의 처리 능력이 한정되기 때문에 대부분 JSON 형태의 페이로드를 발행하는 방식으로 설계한다. 브라우저에서 XML 페이로드를 발행하는 REST 서비스로부터 데이터를 받아 처리하는 건 불가능하진 않지만 별로 효율이 좋지 않다. 어느 브라우저든 자바스크립트 언어 해석기는 다 장착되어 있기 때문에 JSON 형식으로 페이로드를 받아 처리하는 방식이 여러모로 효율적이다.
표준 규격인 RSS/Atom Feed 와 달리 JSON 은 딱히 구조가 정해져 있는 형식이 아니기 때문에 JSON 의 페이로드 구조는 AJAX 설계팀과 논의해 결정하는 것이 일반적이다.
MappingJackson2JsonView 로 XML 만들기
@RequestMapping("/members")
public String getRestMembers(Model model) {
...
return "jsonmembertemplate";
}
반환하는 뷰의 이름만 빼고 위에서 작성한 핸들러 메소드와 동일하다. 이 메소드가 반환한 jsonmembertemplate 이라는 뷰 이름은 MappingJackson2JsonView 뷰로 매핑되는데, 다음과 같이 구성 클래스에 설정할 수 있다.
public class CourtRestConfiguration {
@Bean
public View jsonmembertemplate() {
MappingJackson2JsonView view = new MappingJackson2JsonView();
view.setPrettyPrint(true);
return view;
}
}
MappingJackson2JsonView 뷰는 잭슨2 라이브러리를 이용해 객체를 JSON 으로 바꾸거나 그 반대 작업을 수행한다. 내부적으로는 이 라이브러리의 ObjectMapper 인스턴스가 그 일을 도맡는다.
위의 예시와 같은 코드에서, /members 에 대한 요청이나 /member.* 에 대한 요청 모두 JSON 이 생성된다. 이 때 다양한 페이로드를 제공하기 위해서 다음과 같이 메소드를 추가할 수 있다.
반환 뷰의 이름을 제외한 나머지 로직은 동일한 getMembersXml(), getMembersJson() 두 메소드가 준비되었다. 어느 메소드를 호출할 지는 @RequestMapping 의 produces 속성값으로 결정된다.
이런 식의 구현도 잘 동작은 하겠지만, 애플리케이션 개발 시 지원 뷰 타입마다 메소드를 일일이 중복해서 구현하는 것은 문제가 있다. Helper 메소드를 만들어 사용하면 중복을 줄일 수는 있지만, @RequestMapping 설정 내용은 메소드마다 다르기 때문에 유사한 코드가 여러 메소드에 도배되는 것을 막기는 힘들 것이다.
@ResponseBody 로 JSON 만들기
MappingJackson2JsonView 로 JSON 응답을 생성할 수 있지만 앞에서 언급했듯, 여러 뷰 타입을 지원할 경우 문제가 발생할 수 있다. 이럴 땐 스프링 MVC 의 HttpMessageConverter 를 이용해 유저가 요청한 표현형으로 객체를 변환하는 것이 좋다.
@Controller
public class RestMemberController {
@RequestMapping("/members")
@ResponseBody
public Members getRestMembers() { ... }
}
앞서 설명한 것과 같이 @ResponseBody 는 메소드의 실행 결과를 응답의 본문으로 취급하겠다고 스프링 MVC 에 밝힌다. XML 을 발행하는 것과 마찬가지로 이와 같이 적용할 경우 Members 객체만 반환하면 되고, 구성 클래스에서도 마샬러를 따로 작성할 필요가 없다. (@Controller 를 @RestController 로 바꾸면 @ResponseBody 를 사용하지 않아도 되는 것도 같다)
이제 /members.xml 을 요청하면 XML 을 받고 /members.json 을 요청하면 JSON 을 받는다. 구성 클래스에서 명시적으로 이를 선언하지 않았음에도 어떻게 이게 가능할까? 스프링 MVC 가 클래스패스에 있는 것을 자동으로 감지해 요청에 따라 적절한 HttpMessageConverter 를 등록해 변환하기 때문이다. 이제 데이터를 어떤 뷰로 제공할 것인지에 대한 고민은 하지 않고, 데이터 객체를 그대로 전달하면 스프링이 알아서 적절한 뷰를 제공한다는 것을 확인했다.
3. 스프링으로 REST 서비스 액세스하기
스프링 애플리케이션에서 서드파티 REST 서비스의 페이로드를 사용하려면 어떻게 해야 할까?
서드파티 REST 서비스에 접근하기 위한 방법으로 RestTemplate 클래스를 이용하는 방법이 있다. 이 클래스는 다른 스프링의 *Template 류 클래스와 마찬가지로 장황한 작업을 기본 로직으로 단순화하자는 설계 사상을 따르고 있다. 덕분에 스프링 애플리케이션에서 REST 서비스를 호출하고 반환받은 페이로드를 사용하기 매우 간편하다.
스프링 RestTemplate 클래스는 애당초 REST 서비스를 호출할 의도로 설계된 클래스이므로 주요 메소드가 다음 표에서 볼 수 있듯 HTTP 요청 메소드와 같이 REST 의 기본 토대와 밀접하게 연관되어 있다.
위 표에서 볼 수 있듯, RestTemplate 의 메소드명은 HTTP 요청 메소드로 시작한다. execute 는 사용 빈도가 적은 TRACE 를 비롯, 어떤 HTTP 메소드라도 사용 가능한 범용 메소드이다. (단, execute 메소드가 내부에서 사용하는 HttpMethod Enum 에서 제외된 CONNECT 메소드는 지원하지 않는다)
REST 서비스에서 가장 많이 사용되는 HTTP 메소드는 단연 GET 이다. GET 은 안전하게 정보를 가져오지만 (즉, 데이터 변경이 이루어지지 않지만) PUT, POST, DELETE 등의 메소드는 원본 데이터를 수정하는 수단이므로 REST 서비스의 공급자가 이런 메소드까지 지원할 가능성은 희박하다. 일반적으로 서비스 공급자는 데이터 변경이 필요한 경우 REST 서비스의 대체 수단인 SOAP 프로토콜을 선호한다.
RestTemplate 클래스의 메소드를 대략적으로 살펴봤으니 이번엔 REST 서비스를 스프링 프레임워크에서 자바로 호출해보자. 다음은 서드파티 REST 서비스를 액세스해 그 결과를 표준 출력으로 출력하는 코드이다.
public static void main(String [] args) throws Exception {
final String uri = "http://localhost:8080/court/members.json";
RestTemplate restTemplate = new RestTemplate();
String result = restTemplate.getForObject(uri, String.class);
System.out.println(result);
}
먼저 RestTemplate 객체를 생성한 뒤, getForObject() 메소드를 호출한다. getForObject() 는 브라우저가 REST 서비스 페이로드를 가져오는 것처럼 HTTP GET 요청을 수행한다.
getForObject() 의 호출 결과로 받은 응답을 String 형 변수 result 에 할당한다. 앞서 이 REST 서비스를 브라우저에서 호출한 결과 화면에 표시됐던 내용을 String 형식으로 담는 것이다. 메소드에 전달한 첫 번째 매개변수는 브라우저에서 썼던 것과 동일한 URL 이고, 두 번째 매개변수는 해당 응답의 결과를 어떤 형태로 반환받을 것인지를 의미한다.
위의 코드를 실행하면 브라우저 화면에서 출력됐던 결과와 동일한 문자열이 콘솔 창에 출력될 것이다.
매개변수화한 URL 에서 데이터 가져오기
앞에서 URL 을 호출해 데이터를 가져오는 것은 수행했는데, 만약 URL 에 필수 매개변수를 넣어야 하는 경우는 어떻게 해야 할까? 다행히 RestTemplate 의 메소드는 URL 에 placeholder 를 넣고 나중에 이 곳을 실제 값으로 치환할 수 있다. placeholder 는 @RequestMapping 과 같이 {} 로 삽입할 위치를 표시한다.
public static void main(String [] args) throws Exception {
final String uri = "http://localhost:8080/court/member/{memberId}";
Map<String, String> params = Map.of("memberId", 1);
RestTemplate restTemplate = new RestTemplate();
String result = restTemplate.getForObject(uri, String.class, params);
System.out.println(result);
}
데이터를 매핑된 객체로 가져오기
결과를 String 으로 반환받는 대신 Members/Member 클래스로 직접 매핑해서 사용할 수 있다. getForObject() 메소드의 두 번째 매개변수를 String.class 가 아닌, 매핑할 클래스로 지정하면 해당 클래스에 맞게 응답이 매핑된다.
public static void main(String [] args) throws Exception {
final String uri = "http://localhost:8080/court/member/{memberId}";
Map<String, String> params = Map.of("memberId", 1);
RestTemplate restTemplate = new RestTemplate();
Member result = restTemplate.getForObject(uri, Member.class, params);
System.out.println(result);
}
4. RSS/Atom Feed 발행하기
RSS/아톰 피드는 정보 발행 시 널리 사용되는 수단으로, 보통 REST 서비스를 사용해 액세스한다. 즉, 일단 REST 서비스를 구축한 다음 REST/아톰 피드를 발행할 수 있다. 스프링의 기본적인 REST 지원 기능 외에 RSS/아톰 피드 전용 서드파티 라이브러리를 사용하면 편리하게 구현할 수 있다. 여기서는 오픈소스 자바 프레임워크인 ROME 을 사용했다.
우선, 어떤 정보를 RSS/아톰 피드로 발행할 지를 결정한다. 정보를 가져오는 방법은 여기서 다룰 내용이 아니므로 넘어가고, 발행할 정보를 선택한 다음 RSS/아톰 피드로 구조를 잡아야 하는데 여기서 바로 ROME 이 사용된다.
RSS/아톰 피드는 정보를 발행하는 데 여러 엘리먼트를 활용한 XML 페이로드일 뿐이다. RSS/아톰 피드는 두 형식 모두 공통적인 특징이 있다. 간단히 정리하면 다음과 같다.
피드 내용을 서술하는 메타데이터 영역이 존재한다. (예: 아톰의 <author> 와 <title>, RSS 의 <description> 과 <pubDate>)
순환 엘리먼트로 복수의 정보를 나타낼 수 있다. (예: 아톰의 <entry>, RSS 의 <item>) 각 순환 엘리먼트는 자체 엘리먼트를 가지고 있어 더 자세한 정보를 나타낼 수 있다.
버전이 다양하다. RSS 는 0.90, 0.01 넷스케이프, 0.91 유저랜드, 0.92, 0.93, 0.94, 1.0 을 거쳐 현재 2.0 이 최신 버전이고 아톰은 0.3 과 1.0 버전이 있다. ROME 을 사용하면 버전에 상관없이 자바 코드에서 기용한 정보를 바탕으로 피드의 메타데이터 영역, 순환 엘리먼트를 생성할 수 있다.
RSS/아톰 피드의 구조 및 ROME 의 역할을 간단히 봤으니, 스프링 MVC 컨트롤러에서 유저에게 피드를 표시하는 코드를 살펴보자.
@RestController
public class FeedController {
@RequestMapping("/atomfeed")
public String getAtomFeed(Model model) {
List<TournamentContent> tournamentList = new ArrayList<>();
...
model.addAttribute("feedContent", tournamentList);
return "atomfeedtemplate";
}
@RequestMapping("/rssfeed")
public String getRSSFeed(Model model) {
List<TournamentContent> tournamentList = new ArrayList<>();
...
model.addAttribute("feedContent", tournamentList);
return "rssfeedtemplate";
}
}
/atomfeed 을 getAtomFeed() 메소드에 /rssfeed 을 getRSSFeed() 메소드에 매핑했다. 이들 메소드엔 TournamentContent 객체 리스트가 tournamentList 변수로 선언되어 있다. 여기서 TournamentContent 객체는 일반 POJO 이다. 두 메소드는 반환 뷰에서 이 리스트에 접근할 수 있도록 Model 객체의 속성에 할당한 뒤 각각 논리 뷰를 반환한다. 논리 뷰는 스프링 구성 클래스에 다음과 같이 정의한다.
public class RestConfiguration {
@Bean
public AtomFeedView atomfeedtemplate() {
return new AtomFeedView();
}
@Bean
public RSSFeedView rssfeedtemplate() {
return new RSSFeedView();
}
}
스프링은 ROME 기반으로 제작된 RSS/아톰 전용 뷰 클래스 AbstractAtomFeedView 와 AbstractRssFeedView 를 지원한다. 두 추상 클래스로 인해 RSS/아톰 형식을 세세하게 알지 못해도 뷰를 구현할 수 있다.
다음은 AbstractAtomFeedView 를 상속한 AtomFeedView 클래스로, 논리 뷰 atomfeedtemplate 을 구현한 코드이다.
HTTP (Hyper Text Transfer Protocol) 이란, 인터넷에서 데이터를 주고받을 수 있는 프로토콜이다. 프로토콜은 일종의 규약으로, 이 규약이 정의되었기 때문에 인터넷 상에서 프로그램들이 규약에 맞게 서로 정보를 공유할 수 있도록 한다.
HTTP 의 구조
HTTP 는 애플리케이션 레벨의 프로토콜로 TCP/IP 위에서 동작한다. HTTP 는 상태를 가지지 않는 Stateless 프로토콜이며 Method, Path, Version, Headers, Body 등으로 구성된다.
HTTP 동작
클라이언트, 즉 사용자가 브라우저를 통해 어떠한 서비스를 URL 을 통해 요청 (Request) 을 하면, 서버에서는 해당 요청사항에 맞는 결과를 찾아 사용자에게 응답 (Response) 하는 형태로 동작한다.
HTML 문서만이 HTTP 통신에서 사용되는 유일한 정보 문서가 아니고, Plain Text, Json, XML 과 같은 형태의 정보도 주고받을 수 있다. 보통은 클라이언트 측에서 어떤 형태의 데이터를 요청할 것인지 헤더에 명시하는 경우가 많다.
HTTP 특징
HTTP 메시지는 HTTP 서버와 클라이언트에 의해 해석된다.
TCP/IP 를 이용하는 응용 프로토콜이다. (컴퓨터와 컴퓨터 간의 데이터 전송을 가능케 하는 장치로, 인터넷이라는 거대한 통신망을 통해 원하는 정보를 주고받는 기능을 이용하는 응용 프로토콜)
연결 상태를 유지하지 않는 비연결성 프로토콜이다. (이로 인한 단점을 보완하기 위해 Cookie 와 Session 이라는 개념이 등장했다.)
연결을 유지하지 않는 프로토콜이기 때문에, 요청 - 응답의 방식으로 동작한다.
HTTP 는 암호화되지 않은 평문 데이터를 전송하는 프로토콜이기 때문에, HTTP 로 개인정보 등을 주고 받으면 패킷을 수집하는 것만으로 제 3자가 정보를 조회할 수 있다. 이러한 문제를 해결하기 위해 등장한 것이 HTTPS (Hyper Text Transfer Protocol Secure) 이다.
HTTPS
Hyper Text Transfer Protocol over Secure Socket Layer, HTTP over TLS, HTTP over SSL, HTTP Secure 등으로 불리는 HTTPS 는 HTTP 에 데이터 암호화가 추가된 프로토콜이다. 기본 골격이나 사용 목적 등은 HTTP 와 거의 동일하지만, 데이터를 주고받는 과정에 '보안' 요소가 추가되었다는 것이 가장 큰 차이점이다. HTTPS 를 사용하면 서버-클라이언트 간의 모든 통신 내용이 암호화된다.
특정 파일에 암호를 걸 때처럼 어떤 키를 이용해 잠금을 걸고, 그 키를 이용해 암호를 푸는 것을 생각해보자. 서버-클라이언트 간 통신도 간단하게 생각하면 서버가 하나의 키를 정해 암호화된 페이지를 사용자의 웹 브라우저로 전달하고, 웹 브라우저는 그 키를 이용해 페이지를 복호화하면 될 것이다. 하지만 일반적으로 서버-클라이언트 관계는 일대다 관계를 이루고, 클라이언트는 불특정 다수로 이루어지기 때문에 이처럼 간단한 암호화는 간단치 않다. 그렇다고 키를 단순히 사용자들에게 제공하면 아무나 복호화를 할 수 있기 때문에 암호화의 의미가 사라지게 된다.
HTTPS 는 위와 같은 상황에서 페이지를 암호화한 키가 그 페이지를 요청한 특정 사용자에게만 제공되도록 한다. HTTPS 는 SSL 이나 TLS 프로토콜을 통해 세션 데이터를 암호화하고, SSL 프로토콜 위에서 HTTPS 프로토콜이 동작한다.
암호화 방식
HTTPS 는 공개키 암호화 방식과 공개키의 단점을 보완한 대칭키 암호화 방식을 함께 사용한다. 공개키 방식으로 대칭키를 전달하고, 서로 공유된 대칭키를 사용해 통신하게 된다.
공개키 방식
A 키로 암호화를 하면 B 키로 복호화를 할 수 있다.
B 키로 암호화를 하면 A 키로 복호화를 할 수 있다.
둘 중 하나를 비공개키 (Private Key) 또는 개인키라 부르며, 이는 자신만 가지고 공개되지 않는다.
나머지 하나를 공개키 (Public Key) 라 부르며 다른 사람에게 제공한다. 공개키는 유출되어도 비공개키를 모르면 복호화를 할 수 없기 때문에 안전하다.
공개키 암호화 방식은 다음의 그림을 보면 쉽게 이해할 수 있다.
대칭키 방식
동일한 키로 암호화, 복호화를 할 수 있다.
대칭키는 매번 랜덤으로 생성되어, 키가 유출되어도 다음 사용 시는 다른 키가 사용되기 때문에 안전하다.
공개키보다 빠른 통신이 가능하다.
이러한 SSL 방식의 적용을 위해 인증서를 발급받아 서버에 적용해야 한다. 인증서는 사용자가 접속한 서버가 우리가 의도한 서버가 맞는 지를 보장하는 역할을 한다. 인증서를 발급하는 기관을 CA(Certificate Authority) 라 부른다. 공인인증 기관의 경우 웹 브라우저가 미리 CA 리스트와 함께 각 CA 의 공개키를 알고 있다.
동작 과정
보안적인 부분에 대해서는 자세히 다루지 않고, 인증서 발급부터 사이트가 어떤 방식으로 사용자와 안전하게 통신하는 지를 확인해보자.
※ 아래 그림 및 설명에서, 서버 = 사이트, 클라이언트 = 사용자 로 표현한다.
사이트는 공개키와 개인키를 생성하고, 신뢰할 수 있는 인증 기관 (CA) 에 자신의 정보와 공개키를 관리해 달라는 계약을 한다.
계약을 완료한 인증 기관은 기관만의 공개키와 개인키가 있다. 인증 기관은 사이트가 제출한 데이터를 검증하고, 인증 기관의 개인키로 이를 암호화한다.
인증 기관은 인증 기관의 개인키로 암호화된 인증서를 사이트에 발급한다.
인증 기관은 웹 브라우저에게 자신의 공개키를 제공한다.
사용자가 사이트에 접속하면 서버는 자신의 인증서를 웹 브라우저에 보낸다. 예를 들어, 웹 브라우저가 index.html 파일을 요청하면 서버의 정보를 인증 기관의 개인키로 암호화한 인증서를 받게 되는 것이다.
웹 브라우저는 ③ 에서 미리 알고 있었던 인증기관의 공개키로 인증서를 해독해 검증한다. 그러면 사이트의 정보와 서버의 공개키를 알 수 있게 된다. 이 부분은 보안상의 의미를 갖지는 않고, 단지 해당 서버로부터 온 응답임을 확인할 수 있게 된다.
대칭키를 생성하고, 2. 에서 얻은 서버의 공개키로 대칭키를 암호화해 사이트에 보낸다.
사이트는 개인키로 암호문을 해독해 대칭키를 얻게 되고, 이제 대칭키를 사용해 데이터를 주고받을 수 있게 된다.
HTTPS 의 장단점
HTTPS 는 웹사이트와 사용자 브라우저 사이의 통신을 침입자가 건드리지 못하도록 함으로써 웹사이트의 무결성을 보장해 준다. (침입자라 함은, 악의가 있는 공격자는 물론이고 합법이지만 통신에 침입해 페이지에 광고를 삽입하는 경우도 포함한다.)
가벼운 웹 서핑이라면 HTTP 도 상관없지만, 사용자의 정보를 웹 서버와 주고받아야 하는 경우 HTTP 는 정보 유출의 위험성을 갖는다. HTTPS 는 웹사이트와 사용자 간의 통신을 몰래 수신하는 것을 방지함으로써 보안을 강화한다.
getUserMedia() 를 통한 사진 촬영이나 오디오 녹음, 프로그레시브 웹 앱과 같은 강력한 웹 플랫폼 신기능들은 실행하기 위해 사용자의 명시적인 권한 확인을 필요로 한다. Geolocation API 와 같은 오래된 API 들도 실행 시 권한 확인이 필요하도록 업데이트되고 있는데, HTTPS 는 이러한 권한 허락을 가능케 한다.
네이버, 다음은 물론이고 구글 역시 검색 엔진 최적화 (SEO ; Search Engine Optimization) 관련 내용을 HTTPS 웹사이트에 적용하고 있다. 즉, 키워드 검색 시 상위에 노출되는 기준 중 하나가 보안 요소이다.
모든 사이트에서 텍스트를 암호화해 주고받으면 과부하가 걸려 속도가 느려질 수 있다. (현재는 기술의 발달로 HTTPS 와 HTTP 간 속도 차이가 미미하다고 한다.)
HTTPS 를 지원한다 해서 무조건 안전한 것은 아니다. 신뢰할 수 있는 인증 기관이 아니라 자체적으로 인증서를 발급할 수도 있고, 신뢰할 수 없는 인증 기관을 통해 인증서를 발급받을 수도 있기 때문이다.
REST 에 대해 공부를 하다가, RESTful API 란 무엇일까를 생각하게 됐다. REST 하게 프로젝트도 진행했고, 프로젝트 진행을 위해 공부를 했던 것 같은데 정확하게 REST 라는 것이 어떤 의미인지는 알지 못하고, 'URI 는 자원을 명시하도록 하고 HTTP Method (POST, GET, PUT, DELETE) 를 통해 CRUD 를 정의한다.' 라고만 알고 있어 REST 가 어떤 의미를 갖는지, REST API 는 무엇인지 자세히 공부할 필요성을 느끼게 됐다.
REST 란?
REST 는 REpresentational State Transfer 의 약자로, 위키에서는 이 용어를 World Wide Web 아키텍처의 설계 / 개발을 가이드하기 위해 만들어진 소프트웨어 아키텍처 스타일이라 정의한다.
REST 는 일련의 원칙들을 정의해서 웹 설계 및 개발 시 가이드라인을 주고 있는데, 이러한 원칙을 잘 지켜 개발된 API 를 RESTful API 라 부른다.
RESTful API 는 다음의 구성으로 이루어져있다.
URI - 자원 (Resource)
HTTP Method - 행위 (Verb)
표현 (Representation)
REST 의 특징
1. Uniform Interface
유니폼 인터페이스는 URI 로 지정한 자원에 대한 조작을, 통일되고 한정적인 인터페이스로 수행하는 아키텍처 스타일을 의미한다.
2. Stateless
REST 는 상태를 갖지 않는 특성을 갖는다. 다시 말해, 작업을 위한 상태 정보를 따로 저장하거나 관리하지 않는다. 세션 정보나 쿠키 정보를 별도로 저장하고 관리하지 않기 때문에 API 서버는 들어오는 요청을 단순 처리하면 된다. 이로 인해 서비스의 자유도가 높아지고 서버에서 불필요한 정보를 관리하지 않음으로 인해 구현이 단순해진다.
3. Cacheable
REST 의 가장 큰 특징 중 하나는 HTTP 라는 기존의 웹 표준을 그대로 사용하기 때문에, 웹에서 사용하는 기존의 인프라를 그대로 활용할 수 있다는 것이다. 따라서 HTTP 가 가진 캐싱 기능을 적용할 수 있다. 캐싱 기능을 사용하려면 HTTP 프로토콜 표준에서 사용하는 Last-Modified 태그나 E-Tag 를 이용하면 캐싱의 구현이 가능하다.
4. Self - Descriptiveness
REST 의 또 다른 특징 중 하나는 REST API 의 메시지만 보고 무슨 의미를 갖는 지 쉽게 이해할 수 있도록 자체 표현 구조로 되어있다는 점이다.
5. Client - Server 구조
REST 서버는 API 제공, 클라이언트는 사용자 인증이나 컨텍스트 (세션, 로그인 정보) 등을 직접 관리하는 구조로 각각의 역할이 명확히 구분되기 때문에 클라이언트와 서버에서 개발해야 할 내용이 명확해지고, 서로 간의 의존성이 줄어들게 된다.
6. Hierarchical System
REST 서버는 다중 계층으로 구성될 수 있으며 보안, 로드 밸런싱, 암호화 계층을 추가함으로써 구조상의 유연함을 갖출 수 있고 프록시, 게이트웨이와 같은 네트워크 기반의 중간 매체를 사용할 수 있게 한다.
REST API 디자인 가이드
REST API 설계 시 가장 중요한 항목은 다음의 두 가지로 요약할 수 있다.
URI 는 요청한 정보의 자원을 표현해야 한다.
자원에 대한 행위는 HTTP Method (POST, GET, PUT, DELETE) 로 표현한다.
1. REST API 중심 규칙
1) URI 는 정보의 자원을 표현해야 한다. (리소스명으로는 동사보다는 명사를 사용)
GET /members/delete/1
위의 방식은 REST 의 원칙을 제대로 적용하지 않은 API 이다. URI 는 자원을 표현하는 데 중점을 두어야 한다. delete 와 같은 행위에 대한 표현이 URI 에 들어가선 안 된다.
2) 자원에 대한 행위는 HTTP Method(POST, GET, PUT, DELETE) 로 표현한다.
위의 잘못된 URI 를 HTTP Method 를 적용해 표현하면 다음과 같이 표현할 수 있다.
DELETE /members/1
정보를 가져올 때는 GET, 정보 추가 시의 행위를 표현할 때는 POST Method 를 사용해 표현한다.
URI 에 포함되는 모든 글자는 리소스의 유일한 식별자로 사용되어야 한다. URI 가 다르다는 것은 리소스가 다르다는 것이고, 역으로 리소스가 달라지면 URI 또한 달라져야 한다. REST API 는 분명한 URI 를 만들어 통신을 해야 하기 때문에 혼동을 주지 않도록 URI 경로의 마지막에는 슬래시 문자(/) 를 포함하지 않는다.
RESTful API 는 메시지 바디 내용의 포맷을 나타내기 위한 파일 확장자를 URI 안에 포함시키지 않는다. 대신 다음과 같이 Accept Header 를 사용해 API 를 호출한다.
GET /members/soccer/345/photo HTTP/1.1 Host: restapi.example.com Accept: image/jpg
3. 리소스 간의 관계 표현 방법
REST 리소스 간에는 연관 관계가 있을 수 있고, 이런 경우 다음과 같은 방법으로 표현한다. (/ 리소스명 / 리소스 ID / 연관 관계가 있는 다른 리소스명)
GET /users/{userid}/devices (일반적으로 'has' 의 관계를 표현할 때)
만약에 리소스 간 연관 관계가 단순 소유 관계가 아닐 경우, 이를 서브 리소스에 명시적으로 표현할 수 있는 방법이 있다. 예를 들어, 사용자가 '좋아하는' 디바이스 목록을 표현해야 할 경우 다음과 같이 표현할 수 있다.
GET /users/{userid}/likes/devices (관계명이 애매하거나 복잡한 관계를 표현하고자 할 때)
4. 자원을 표현하는 Collection 과 Document
Collection 과 Document 에 대한 이해는 URI 설계를 더 쉽게 할 수 있도록 도와준다. 도큐먼트는 단순히 문서로 이해할 수도 있고, 하나의 객체로 이해할 수도 있다. 컬렉션은 문서들의 집합, 객체들의 집합이라고 생각하면 이해하는 데 편할 수 있다. 컬렉션과 도큐먼트는 모두 리소스라 표현할 수 있으며 URI 에 표현된다. 다음의 예를 살펴보자.
http://restapi.example.com/sports/soccer
위의 URI 를 보면, sports 라는 컬렉션과 soccer 라는 도큐먼트를 표현하고 있다. 좀 더 자세한 예를 보자.
sports, players 컬렉션과 soccer, 13 (13번 선수) 를 의미하는 도큐먼트로 URI 가 이루어진다. 여기서 중요한 점은, 컬렉션은 URI 에서 복수로 표현하고 있다는 점이다. 좀 더 직관적인 REST API 를 설계하기 위해 컬렉션과 도큐먼트를 사용할 때 단수/복수 를 잘 지킨다면 좀 더 이해하기 쉬운 URI 를 설계할 수 있다.
5. HTTP 응답 상태 코드
마지막으로, 응답 상태코드를 간단히 살펴보자. 잘 설계된 RESTful API 는 URI 만 잘 설계된 것이 아니라 그 리소스에 대한 응답을 잘 내어주는 것까지 포함되어야 한다. 정확한 응답의 상태코드만으로도 많은 정보를 전달할 수 있기 때문에 응답의 상태코드 값을 명확히 하는 것은 생각보다 중요하다. 응답에 대한 상태 코드로 200 과 4XX 정도의 코드만을 사용하고 있다면 처리 상태/결과에 대한 더 명확한 상태 코드값을 사용하는 것이 필요하다.
주로 사용하는 몇 가지의 상태코드는 다음과 같다. 상태 코드들에 대한 자세한 정보는 여기서 확인할 수 있다.
Status Code
Description
200 OK
클라이언트의 요청을 정상적으로 수행함
201 Created
클라이언트가 요청한 리소스가 정상적으로 생성됨
301 Moved Permanently
클라이언트가 요청한 리소스에 대한 URI 가 변경됨 (응답 시 Location Header 에 변경된 URI 를 명시)
400 Bad Request
클라이언트의 요청이 부적절함
401 Unauthorized
클라이언트가 인증되지 않은 상태에서 보호된 리소스를 요청함 (예: 로그인하지 않은 유저가 로그인했을 때 요청 가능한 리소스를 요청)
403 Forbidden
유저 인증상태와 관계 없이 응답하고 싶지 않은 리소스를 클라이언트가 요청함 (403 보다는 400 이나 404 의 사용을 권장. 403 응답 자체가 해당 리소스가 존재한다는 의미를 갖기 때문)
※ 튜플 (Tuple) : 릴레이션 (테이블) 을 구성하는 각각의 행, 속성의 모임으로 구성된다. 파일 구조에서는 레코드와 같은 개념.
튜플의 수 = 카디널리티 = 기수 = 대응수
하나의 릴레이션에는 수많은 튜플들이 존재한다. 고객 정보를 저장한 릴레이션에는 많은 고객들에 대한 튜플들이 존재하며, 각 튜플들 간에는 중복되는 속성값이 발생할 수 있다.
예를 들어 이름, 나이, 사는 곳 등의 정보가 중복될 수 있는데, 이 때 각각의 고객(튜플)을 구분하기 위한 기준이 되는 속성이 필요하다. 이것을 우리는 "키" 라고 부르며, 하나의 속성 또는 여러 속성들의 집합으로 표현할 수 있다.
키의 종류로는 슈퍼키, 후보키, 기본키, 대체키, 외래키 가 있다.
최소성, 유일성
각각의 키에 대해 공부하기 전에, 최소성과 유일성이라는 개념에 대해 정리하고 넘어가려 한다.
유일성
유일성이란, 하나의 키값으로 튜플을 유일하게 식별할 수 있는 성질을 말한다. 위에서 언급했듯 여러 개의 튜플이 존재할 때 각각의 튜플을 서로 구분할 수 있는 속성이 존재해야 한다. 한 마디로 말하자면, 각각의 튜플은 유일해야 한다는 뜻이다. 예를 들어 어떤 릴레이션에 (주민번호, 나이, 사는 곳, 혈액형) 이라는 속성이 존재한다고 하자. 이 때 나이, 사는 곳, 혈액형 은 모두 충분히 중복될 수 있는 속성들이다. 하지만 주민번호는 모두 다르기 때문에 주민번호 속성에서 중복은 절대 발생할 수 없다. 이 릴레이션에서 키는 주민번호로 지정될 것이며, 이렇게 각각의 튜플을 구분할 수 있는 성질을 유일성이라고 표현한다.
최소성
최소성이란, 키를 구성하는 속성들 중 가장 최소로 필요한 속성들로만 키를 구성하는 성질을 말한다. 쉽게 말해, 키를 구성하고 있는 속성들이 진짜 각 튜플을 구분하는 데 꼭 필요한 속성들로만 구성되어 있는지를 의미한다. 예를 들어 위와 같이 (주민번호, 나이, 사는 곳, 혈액형) 릴레이션에서 (주민번호, 나이) 가 키로 지정이 되어 있다면, 당연히 이 키는 각 튜플을 구분할 수 있다. 주민번호와 나이가 모두 같은 사람은 세상에 존재하지 않기 때문에 그렇게 말할 수 있지만, 더 간단하게 주민번호가 중복되는 사람은 세상에 존재하지 않는다. 그렇기 때문에 (주민번호, 나이) 로 지정된 키는 최소성을 만족하지 않고 키에서 나이를 뺀 주민번호 만 키로 지정이 될 경우, 이 키는 최소성을 만족한다고 할 수 있다.
1. 슈퍼키 (Super Key) ; 유일성 O, 최소성 X
슈퍼키는 유일성의 특성을 만족하는 속성 또는 속성들의 집합을 의미한다.
키 값이 같은 튜플은 존재할 수 없다. 예를 들어 (고객 아이디) 의 경우 아이디가 같은 고객은 없기 때문에 슈퍼키가 될 수 있다. 하지만 (직업, 나이, 등급) 의 경우 나이, 직업, 등급이 같은 고객은 충분히 있을 수 있기 때문에 슈퍼키로 사용할 수 없다. 하지만 (고객 아이디, 직업, 나이, 등급) 의 경우는 고객 아이디가 각 튜플을 구분할 수 있는 속성이기 때문에 슈퍼키가 될 수 있다. 이처럼 슈퍼키는 유일성은 만족하지만 최소성은 만족하지 않는 키를 의미한다.
2. 후보키 (Candidate Key) ; 유일성 O, 최소성 O
후보키는 슈퍼키 중 최소성을 만족하는, 즉 유일성과 최소성을 모두 만족하는 속성 또는 속성들의 집합이다. 위의 슈퍼키에서 들었던 예시에서 (고객 아이디, 직업, 나이, 등급) 은 각 튜플을 유일하게 식별할 수 있으므로 유일성은 만족한다. 하지만 여기서 직업, 나이, 등급 정보가 굳이 필요할까? 이 속성들은 튜플 간에 중복되는 속성값을 가지고 있고, 이 속성들이 포함되어 있지 않은 (고객 아이디) 만으로도 튜플의 식별에는 전혀 문제가 되지 않는다. 그러므로 위의 키에서 직업, 나이, 등급을 제외한 (고객 아이디) 는 최소성을 만족하며 후보키가 될 수 있다.
3. 기본키 (Primary Key) ; 후보키 중 선택받은 키
이렇게 각 튜플을 구별할 수 있으며 유일성과 최소성을 모두 만족하는 후보키가 구해졌다. 후보키는 한 테이블 내에서 여러 개 존재할 수 있는데, 여기서 우리는 여러 후보키 중 하나를 택해 사용해야 하며 여기서 선택된 키가 기본키가 된다. 하지만 모든 후보키가 기본키가 되는 것은 아니고 기본키를 선택함에 있어서 다음의 기준을 통과해야 한다.
NULL 값을 가질 수 있는 속성이 포함된 후보키는 기본키로 부적절하다.
값이 자주 변경될 수 있는 속성이 포함된 후보키는 기본키로 부적절하다.
단순한 후보키를 기본키로 선택한다.
속성
NULL 값을 가질 수 없다. (개체 무결성의 첫번째 조건)
기본키로 정의된 속성에는 동일한 값이 중복되어 저장될 수 없다. (개체 무결성의 두번째 조건)
4. 대체키 (Alternate Key) ; 후보키 중 선택받지 못한 키
대체키는 기본키로 선택받지 못한 후보키들이다. 이름에서 알 수 있듯 대체키는 기본키를 대신할 수 있는 자격은 있지만, 3-1 ~ 3-3 의 조건에 부합하지 않아 기본키로 선택받지 못한 키들을 의미한다. 대체키는 '보조키' 라는 이름으로도 불린다.
5. 외래키 (Foreign Key) ; 다른 릴레이션의 기본키를 참조
외래키는 관계를 맺고 있는 릴레이션 R1, R2 에서 릴레이션 R1 이 참조하고 있는 릴레이션 R2 의 기본키와 같은 R1 릴레이션의 속성이다. 다시 말해 다른 릴레이션의 기본키를 그대로 참조하는 속성 또는 속성들의 집합이 외래키이다. 외래키는 릴레이션 간의 관계를 올바르게 표현하기 위해 필요하다.
속성
외래키로 지정되면 참조 테이블의 기본키에 없는 값은 입력이 불가하다. (참조 무결성 조건)
위의 릴레이션에서 고객 릴레이션은 사이트에 가입한 고객에 대한 데이터를 가지고, 주문 릴레이션은 어떤 제품을 어떤 고객이 주문했는지에 대한 데이터를 다룬다. 주문 릴레이션에는 어떤 고객이 어떤 제품을 '언제, 얼마나, 얼마에' 에 대한 정보가 있을 것이다. 그리고 각 튜플을 구분할 수 있는 기본키(주문번호)가 있을 것이다.
여기서 주문 릴레이션은 고객의 정보를 모두 저장할 필요가 없다. 단지 고객 릴레이션에서 튜플을 구분할 수 있는 기본키가 되는 속성만을 가지고 있으면 된다. 이렇게 고객 릴레이션의 기본키(고객 아이디)를 참조하는 주문 릴레이션의 속성을 외래키(주문 고객)라 한다. 외래키는 관계를 맺은 릴레이션의 기본키를 참조하고 있으며, 이 때 중요한 점은 기본키와 기본키를 참조하는 외래키의 도메인 또한 반드시 같아야 한다는 것이다.
※ 도메인 (Domain) ; 데이터베이스에서 도메인이란, 릴레이션에 포함된 각 속성들이 가질 수 있는 값의 집합이라 할 수 있다. 도메인이라는 개념이 필요한 이유는 릴레이션에서 본래 의도했던 속성값들만 데이터로 저장되고 관리하기 위해서이다. 예를 들어 '성별' 이라는 속성이 있을 때 이 속성이 가질 수 있는 값은 '남' 또는 '여' 일 것이다. 데이터베이스 설계자가 성별의 도메인으로 'SEX' 를 정의하고 그 값을 '남', '여' 로 지정하면 '성별' 이라는 속성은 'SEX' 도메인에 존재하는 값만을 가질 수 있다. 이렇게 도메인을 정의하면 사용자들이 실수로 도메인 외의 값을 입력하는 것을 방지할 수 있다.
도메인의 이름은 속성의 이름과 같을 수도, 다를 수도 있고 하나의 도메인을 여러 속성에서 공유하는 것 또한 가능하다.